import torch
import string
CHARACTERS_TO_FILTER = string.punctuation + " \n"
def is_answer_yes_no(answer):
return answer in ["Yes", "No"]
def postprocess_response(response):
while response and response[-1] in CHARACTERS_TO_FILTER:
response = response[:-1]
return response
def train(
ppo_trainer,
tokenizer,
generation_kwargs,
get_rewards,
script_args, config,
):
n_epochs = config.steps // len(ppo_trainer.dataloader)
for epoch in range(1, n_epochs + 1):
loop = tqdm(
enumerate(ppo_trainer.dataloader, 1),
total=len(ppo_trainer.dataloader), leave=False
)
for batch_idx, batch in loop:
# Get the input tensors
question_tensors = batch["input_ids"]
# Get the generations
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
batch_size=script_args.generator_batch_size,
**generation_kwargs,
)
responses = tokenizer.batch_decode(
response_tensors, skip_special_tokens=True,
spaces_between_special_tokens=False
)
# Postprocess the responses
if script_args.postprocess_responses:
responses = [postprocess_response(x) for x in responses]
batch["response"] = responses
# Compute the rewards (scores)
texts = [q + " " + r for q, r in zip(batch["query"], batch["response"])]
rewards = get_rewards(texts)
# Replace reward for undesired answers to -1
mask = [not is_answer_yes_no(x) for x in batch["response"]]
mask = torch.tensor(mask, dtype=torch.bool) # cast to tensor
rewards[mask] = -1
# Make the rewards a list of tensors
rewards = [x for x in rewards]
# Run PPO step
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
ppo_trainer.log_stats(stats, batch, rewards)Hello, World!
This blog post discusses the main ideas behind my thesis for the MPhil in Machine Learning and Machine Intelligence degree at the University of Cambridge. You can read the full thesis here, or check the associated GitHub repository.
The main idea behind the project is trying to build a reward models that reward “truthfulness” in a scalable fashion, which current state-of-the-art methods, such as reinforcement learning from human feedback (RLHF), are not capable of (note that we use quatations because we defined “truthfulness” in a narrow sense and mean only the performance on binary question-aswering tasks, see the thesis pdf for more details). Specifically, methods that discover latent knowledge, such as CCS, are used to determine whether a piece of input text is truthful or not. Such linear probes are then combined with pre-trained language models to make up reward models, which are used in reinforcement learning RL fine-tuning to improve the “truthfulness” of large language models (LLMs).
These reward models can be trained by using transformed versions of existing datasets, thus relaxing the requirement to collect large numbers of human preference data, as is usual in RLHF. We find that using our reward models along with a few regularization techniques (discussed below) can already be used to improve the “truthfulness” of pre-trained LLMs by up to 1.6%, as measured on the TruthfulQA benchmark. Importantly, such an improvement is achieved without sacrificing the models’ performance on more general NLP tasks (we evaluate on the Open LLM Leaderboard tasks).
Although our method serves as a proof of concept on how hallucinations in LLMs could be tackled in the future, it still has many limitations. For one, the current best DLK methods still have a long way to go in terms of robustness. Moreover, our method only tackles the narrow definition of “truthfulness”, and even though the accuracy on TruthfulQA improves too, many would argue that it is still not a very good proxy for actually reducing levels of hallucination in LLMs. Finally, we found that the pre-trained models that we would fine-tune using RL had to be already quite capable, otherwise our method would not work.
Main steps
There are four main steps to run the method on new data: 1. Split the dataset and prepare it for reward model training and RL fine-tuning. 1. Train a reward model. 1. Performing RL fine-tuning on some pre-trained LLM. 1. Evaluate the fine-tuned LLM on both target and general NLP tasks.
Steps 1 and 4 are mostly boring and you can find more details about them in the README of the GitHub repository, so we are going to focus on the theory and main code bits for steps 2 and 3.
Reward model training
As discussed in more detail in chapter 3 of the thesis, the reward model is made up of a pre-trained language model with a probe attached at the end.
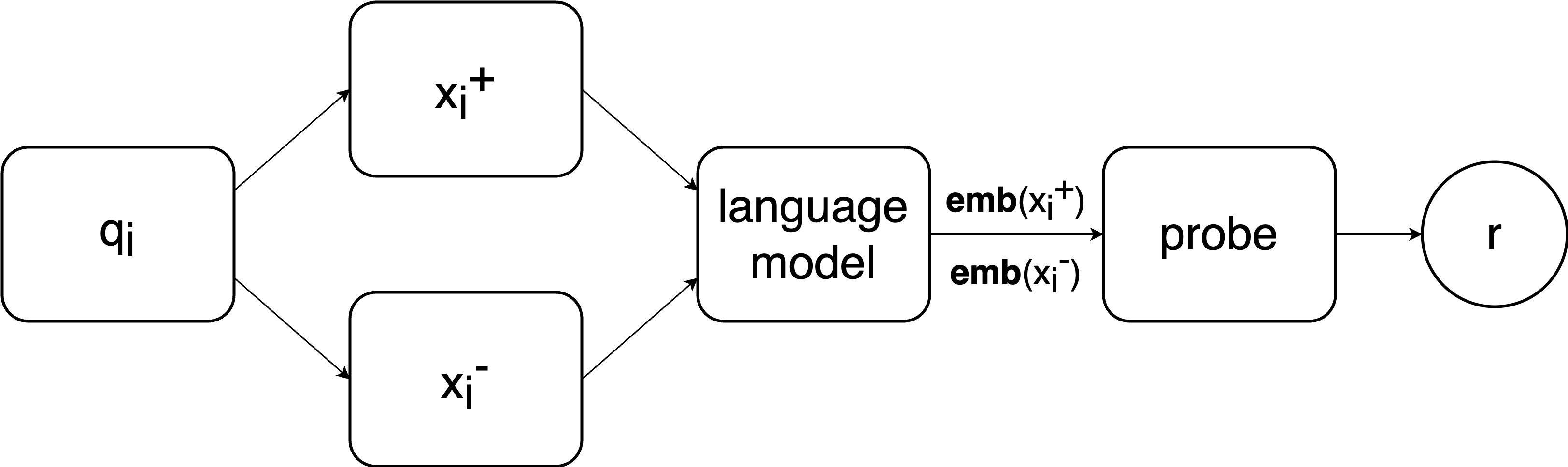
The reward model takes as an input a question \(q_i\) with a binary answer (e.g. “Yes”/“No”), creates a contrastive pair from it and then this contrastive pair \((x_i^+, x_i^-)\) is used to compute a reward (a number between 0 and 1). The reward is computed by recording activations of the last token in a layer of a language model, denoted \(\mathrm{\textbf{emb}}(x_i^+)\) and \(\mathrm{\textbf{emb}}(x_i^-)\). We would try all layers of a language model and pick the one that worked the best. Finally, the embeddings are passed to a logistic classificer which is of the form: \[p(q_i) = \sigma(\textbf{w}^\mathrm{T}(\mathrm{\textbf{emb}}(x_i^+) - \mathrm{\textbf{emb}}(x_i^-)))\] which is the only module with trainable parameters, the vector \(\textbf{w}\). Here, \(\sigma\) is the sigmoid activation function. This output probability denotes the probability that the question \(q_i\) is “truthful” which is what we use as the reward.
There are a few other intricacies, such as how to prompt for “truthfulness” (custom prompts are needed), or how to actually find the optimal parameters vector \(\textbf{w}\), but I will sugeest interested readers to refer to the thesis pdf.
RL fine-tuning
Once we have a reward model, we can plug into an RL algorithm to perform fine-tuning. We used the proximal policy optimization algorithm, as implement in the Transformer Reinforcement Learning (TRL) library from Hugging Face. We found that a few pieces of regularization had to be applied to stabilize the training process. The tricks are:
- Prompting - we found that a specialized prompt had to be devised for each model for the method to work (we mostly focused on the 7B Vicuna models).
- Maximum number of new tokens - we found that setting the number of new tokens to two was enough in our case since answers to our binary questions were short. Additionally, we applied output post-processing to strip any undesirable tokens (see the code below).
- Encouraging the models to only output in the desired format - we want the models to only respond with “Yes”/“No”, but even with specialized prompts the models would still sometimes generate different responses. To tackle this, we tweaked the reward to be -1 if the model does not respond in the desired format, and we would give the usual score from the reward model if the output was what the model was asked for. This encouraged the model to converge to only responding with the required format over time.
To illustrate these concepts, the finel RL training loop looked roughly like the following:
And the generation_kwargs look like the following:
Conclusion
I hope you found this blog as interesting as it was for me to work on this project. I feel like I have learnt a lot during it, for example, I joined multiple ML communities and got involved in discussions with very smart and ambitious people. Perhaps my proudest achievement is making my first open-source contribution to the elk library (link), as well as reported multiple bugs to the big-refactor branch of Language Model Evaluation Harness (link).
I am excited to dive deeper into LLMs-related topics in the future. Feel free to reach out if you have any opportunities on offer!